On Grounded Language Learning and Simulation
Published Tue, Dec 22, 2020
Language seems to be the pinnacle of intelligence. While many animals can communicate, none can do it at the richness or level of complexity as humans. So its not surprising that we have studied language in so much detail trying to understand how language works and what makes human unique in their use of language. There has been a lot of research trying to build computers that can understand and process language in ways similar to a human. Some of the main fields are Natural Language Processing (NLP), computational neuroscience, computational linguistics, artificial intelligence and machine learning. The recent fruits of these labor have resulted in many software architectures such as word2vec, fasttext, CBOW, transformers etc.
These software architectures are so powerful and have become state of the art for text classification, voice recognition, and text generation. And with these new possibilities, many people seem to believe that true computer intelligence is eminent. GPT3 just came out in June 2020 and because it can generate text that looks like it was written by a human, many people think that computers can actually understand and communicate with us now. What has always concerned me with these computer models is that they have zero understanding of the actual world and are just glorified puppets, or as they are called in philosphy, philosphical zombies. And so what ends up happening is that we continue to build models of intelligence on a broken foundation. Yes, these new models are so powerful now that they can hear the words we are saying and can accurately transcribe human speech at 95% accuracy, generate human looking articles, but these computer algorithms still have no idea of what any of it means.
All the initial concepts we learn stem from interacting with our environment, they have physical meaning. A baby’s first concepts come from interacting with the world via touching, falling, grasping, crawling, feeling pain, etc. Although they can’t initially say these words, they do have some understanding of using these concepts to interact with the world and change their sensory inputs via their actions. Their internal representations, the meaning of these concepts, therefore must have some representation that captures the interaction between themselves and their environment, they must contain some form of embodiment, or as they call it in the cogntive science field, embodied cognition.
Just think about what these common words mean to you: up, balance, behind, ahead, heavy, noisy, smooth, and rough. Those words all have their meaning derived from our interactions with the environment and as our understanding of the world grows, the way we use concepts grows into more abstract forms. For example, the concept “balance” is first understood as standing upright in the world and distributing your weight and gait in a way that you don’t fall over. As your knowledge grows, you learn that you can apply balance to any kind of physical object and then later apply it to any abstract thing like balancing multiple responsibilities.
Another example, the concept “rough”. We first learn about the concept “rough” from touching certain physical objects like wood, sandpaper, cement, etc. “Rough” means to have uneven or irregular surface. Later, people learn to apply “rough” to things that are not completely finished like a rough draft or apply it to situations that didn’t finish effortlessly like a “rough night” or a “rough trip”. The concept “rough” is used where more physical exertion must be applied than normal or expected.
Contrast that with the concept of “smooth”, another concept learned from our interaction with the physical world. “Smooth” means having an even and regular surface. We first learn about this concept from touching objects like walls, ice, certain plastics, etc. Over time we apply it to movement such as walking and then move up the abstraction ladder and apply it to any situation that was done without effort, ie there was less physical exertion applied than normal. I had a smooth date or the interview went smoothly.
Another example, the concept “crumble” is to break into small fragments. As kids we play with toy blocks and sand and we see that we can collect them, stack them, and watch them fall apart due to gravity . Over time we learn to apply this concept of falling apart to more and more abstract concepts: the building crumbled, our relationship crumbled, NATO crumbled, etc.
Lets move on to abstract concepts. The definition of “proposal” is to put forward an idea for consideration. So you take something that others don’t see or know about and you move it, typically with your hands, in front of everyone so that they can view it. So there is a physical component involved whether you are proposing something in person or over email. The concept “to impose” is to force something to be put in place. Impose is always used in an abstract sense like imposing taxes or imposing your opinion on others, but to understand the concept “to impose” you must understand concepts like “to be forced” and “to be blocked”, which are all centered understood from the physics and integrations of our environment.
We can keep going over the root of these concepts, but the main point I want to get across is that EVERY concept we understand has some portion of its meaning derived from interactions between ourselves and the physical world. Meaning is grounded in our physical world from the need to survive. These interactions with our world are important to learn cause and effect. With every interaction with our world and daily objects, we learn the results of us exerting our will onto objects. If I push a rock over a ledge, it will fall and may kill my prey. If I move my legs fast and continuously, I will move faster, my heart rate will increase, and I may escape from this lion. If I knock over this cup of liquid, the floor gets wet and slippery. If I move this switch, it becomes lighter or darker in the room. Without all these interactions, its NOT possible to understand more abstract concepts like homework, deadlines, proposals, and calculus.
As of to date, our machine learning models have no way to store these interactions, nor do we have the data available in a meaningful way for a computer to understand it. Just parsing large corpuses of text is not enough to understand. As adult humans, we are often thinking in abstract terms, but without grounded knowledge in the real world, it makes no sense and that goes the same for computers.
Lets look at how computers store representations. Word2vec, a famous deep learning language reprentation model, in more detail. Each word is represented as a vector where each element in the vector is a number from 0 to 1 representing how close another word is to the main word. So for example, the vector for the word “king” will have words like “queen”, “royalty”, and “crown”, near it and so they a number close to 1, while words like “dog”, “haircut”, and “window” will most likely get assigned a number closer to 0. The algorithm is self surpervised, it parses large bodies of text and is able to automatically build its model and so needs minimal help from a human to learn. From only reading text, this model learns and stores no information about the physical world, no interactions, only what words are typically near it.
In the image below, you can see what the vectors look like for a dataset of 5 words.

So, If you try to find any sort of meaning in those vectors, you will essentially be going in circles, as each vector just leads to another vector round in round like a merry-go-round.
Given all this, I’ve been contemplating on how you could train computers to learn grounded meaning, how could we teach computers about our physical world,what would the data structure look like, and what would you need to build this. To be honest, I don’t really know, there are many possible directions and there is a growing body (no pun intended) of research in the space.
When we talk about interactions with our world, we are talking about perceiving the world through our senses. Most animals, including humans have access to 5 broad categories of senses: touch, taste, smell, vision, and hearing. When we think of touch, we usually think of fingers, but our whole skin is a touch sensor and is also the largest organ of our whole body. Our sense of touch is actually compromised of many types of sensors. Our bodies have proprioception receptors, which sense where all of our body parts are in relation to each other, temperature sensing neurons, pressure sensing cells, merkel cells which detect different textures, head direction cells and more. Neuroscience is still very early in understanding all the types of sensors and cells our bodies have.
So if want to teach a computer how to interact with our world, it would make sense that it would need some kind of sensors. Computer algorithms have a form of vision and can process images and videos very efficiently. But for the interactions we have been talking about, vision does not seem to be the right modality to capture the richness of perceptual experience necessary to ground meaning. In fact, contrary to trend of most machine learning research, I don’t believe vision is necessary at all. Helen Keller has led me to believe that the massive blob of sensors we call touch is the key area of focus. Due to an illsness, she was blind and deaf starting from 19 months of age and lived until the age of 87 years. She had no vision and hearing for practically her whole life and never had those sensory experiences in her conscious life! She wrote several books and her favorite of mine is “The World I Live In”. If you didn’t know she was missing her senses, you would not be able to tell. She discusses what consciousness is like and what words mean to her. For example, when she thinks about the concept “duty”, she imagines a straight line, rigid and never leaving its course. “When I think of hills, I think of the upward strength I tread upon. When water is the object of my thought, I feel the cool shock of the plunge and the quick yielding of the waves that crisp and curl and ripple about my body”. She contributes her intelligence to her hands and sense of touch. I highly recommend you read her book.
So with a computer, how would you give it access to all these sensors? You could try building hardware: robots that interact with our world via sensors. If you go down this route, you will run into many problems. It is slow and expensive to do a “build and test” cycle as you need to physically build your robot. The sensors you give to the robot may be inaccurate, wrong, or most likely don’t even currently exist to measure the things we may need. And so every iteration of the robot you build may be missing critical functionality and to develop the right version is just not practical, so that leaves software.
You could build software simulations of a world and your character (typically called a learning agent in machine learning). Video games do this every day with games like Grand Theft Auto, World of Warcraft, Doom, etc. These games all have simplified physics engines that mimic parts of our reality, ignore other parts, and exaggerate others. With any simulated software, you need to pick and choose which of the parts of the world you need to simulate accurately because your computational power is limited. Do you focus on gravity, collision detection, friction interactions, accurate light interactions, biochemistry reactions, temperature, etc. The list of possible physical phenomenons to model in simulation is too long and we have no idea what is required for intelligence to emerge. On top of that, building these physics engines is a very labor intensive process, not some tiny project. So we have to go with an open source engine like Bullet or PhysX.
Anyway, so I wanted to experiment with building a dataset that could teach physical interactions to a computer. Instead of thinking about it for too long and getting stuck, I wanted to start experimenting with a live system immediately. So….. I took a children’s dictionary, collected all 4000 words/concepts, put them into a (spreadsheet)[https://concepts.jtoy.net/concepts], manually analyzed all the words, and sorted them in different ways: part of speech, physical interaction level, abstraction level, etc. I then took 100 words that I thought made a good representation of core language concepts along with some harder concepts and coded up mini simulations that displayed their “definition” of the word as little cartoons. With this dataset I have collected, I consider each word from the children’s dictionary to be interchangeable with concepts. I put all my work online in a project I call “ConceptNet”. I focused mostly on physical action words (verbs) versus nouns, adjectives, and abstract verbs. Each simulation uses basic shapes such as circles and squares to represent bodies. Each simulation is programmed with some randomness, so they are different every time you view them. I created 6 distinct environment types to represent the concepts: a 2D overhead world with physics, a 2D world without physics, a 3D world with physics, a 3D world without physics, a 2D sideview world with physics, and a 2D sideview world without physics. Many of the simulations are crude and basic, but hopefully clear.
I wrote all the code in Javascript so that the results could be viewed by anyone with a browser. I used a library called p5js to do all the drawing, matter.js for the 2D physics engine, and XXX for the 3D physics engine.
Here is the simulation for the verb “to leak”:
Here is the simulation for the verb: “to meet”
Here is the simulation for the verb: “to rotate”
In building this proof of concept (POC) I was able to explore a lot of ideas, I learned a lot, and now I have even more questions. I’ve written about somof my findings and next steps below.
Parts of Speech
In English and many other languages, the main parts of speech (POS) are nouns, verbs, and adjectives. While reading through the children’s dictionary, I noticed many words have definitions in different parts of speech. For example, “complete” is an adjective and a verb. Black can be used as a noun, adjective, and verb. The color black, describing the color of something, and to make something black. Most words I looked at had definitions for both verbs and nouns. For example “repeat” is used as a verb:”to do something again” and as a noun: “an event or action where something is done again”. Another example is the concept “cover”, as a verb it means “to put something on top or in front to protect or conceal it” and as a noun it means “a thing which lies on or over something to conceal or protect it”. Many of the words and concepts we learn transfer easily from action to object and vice versa. There are rules and abstractions that allow us to “stretch” the definition out so we can use these concepts in different ways. A computational data structure would most likely store definitions that would allow fluidity and stretching. In writing simulations for adjectives, I found that adjectives are just really a way to show things that are different from normal, where oftentimes you use yourself as your baseline for normal. So when we say someone is fat, we are saying they are fatter than average or fatter than myself. The same for smart, brave, calm, eager, and every other adjective. So to draw these in simulation, I showed a transition between 2 states: what is considered normal and second state showing the different adjective. For verbs I always showed an agent moving around and performing the verb. For nouns, I tried to show the object in a situation where its specific properties where highlighted. For example, for the concept “cliff”, I showed other objects on a cliff that would fall off the cliff.
Abstractions
The definition of “to complete” is “to make something whole or perfect” or “to finish making or doing”. The simulation I did for “to complete” is very specific, it shows an agent collecting boxes to form a much larger box. I think it is as clear as possible given the constraints, but with all these simulations, we know they are crude simplifications. The holy grail for these models it to be able to store an abstract representation. Computer models are too rigid and do not have the flexibility that humans seem to possess. When I look at the simulation for “to complete”, I wonder how could a computer represent this in an abstract way. Is it simply a combination of its sub definitions: “to make” “something” “whole or perfect”? Is it stored as a clear distinct entity or as a web of meaning? Completing something can require a variable amount of time, ie completing your PhD takes longer than completing your homework,which takes longer than finsihng your food. It seems like the concept “to complete” can be applied to any kind of situation like homework, food, puzzles, or anything with a goal or ending. Its as if the mind learns a general computation for “to complete” that can run on almost any other input it receives similar to how a computer circuit is built to do specific computations for certain data types.
Points of views
Since I made many of these simulations with basic primitives, I often had many of the simulations look the same for many words. For example “to guide” vs “to follow”. Both of those words involve multiple parties where one is guiding and one is following, so it depends on which one you are focusing on to describe who is doing what. If you focus on the guide, then they are guiding, and if you focus on the follower, then they are following.
When describing a situation, every person will usually describe it a little differently because they focus on different things. For example if you see 2 people are fighting, you may choose to describe the situation with the words: to fight, to attack, to punch, to hurt, to beat, etc. Those words are all similar and can describe the situation.
choosing which aspects of the world to model
I spoke about the difficulty in modeling physics earlier. I was unable to simulate a few concepts because the physics engine wasn’t powerful enough. “To fold” would require a physics engine that modeled bending on hard bodies (like metal) or soft bodies(like skin or cloth). I also could not showcase any concepts relating to liquids or air like “to dry”, “wet”, “to irrigate”, “to inflate”, “to puff”, “to blow”, “to breath”, “to boil”, “to paint”, “to rinse”, and related concepts because the physics engines I experimented with didn’t support these.
Our computers are not powerful enough to model everything in our world. So instead, we carefully pick and choose certain aspects to focus on in and implement. This is not just true for our model, but for all computational models. For this prototype, I just wanted to get a sense for what would need to be developed further. With the concepts I focused on, one area that I kept seeing was related to friction. The concepts “smooth”, “rough”, “pressure”,”to dodge”, “getting crushed”, “to bend”, “collision”, “to ascend”, and “to fall” are all have concepts related to friction. Friction is a physical phenomenon, it is a measure of the resistance from one object encountering another object. In all those examples I gave and in everyday life, there is often an implied resistance. When we think of resistance, we often think of heaviness, difficulty, pain, slow, or heat. So Our theoritical data structure would need to account for some sort of friction measure.
Emotion
Many concepts are words related to emotion such as “to ache”, “to apologize”, “to argue”, “to astonish”, “to appreciate”, “to cherish”, “to love” and more. These type of emotion related concepts are argubly some of the most important words to humans. Look at all the cherished works from Shakespear as an example. Even before we had working machines we have been debating on whether it is possible for a computer to have emotions. So there is no way we will come up with a fully working model within the scope of this project. I did find an interesting point though. Going back to friction, it is often thought of as a negative concept. The more friction that is involved between objects, the more potential for fire, parts of the objects tearing off, moving slow, and heat being generated. If your own body is involved, then this friction will mostly likely feel like pain. The concepts of liking or disliking something could be modeled after the physical phenomenon of magnetism where objects have different magnetic fields which cause certain objects to attract and repel eachother.
The concept “to decline” means to decrease or get worse. Decrease has a physical basis of going down or becoming less, but why does it have a negative basis of “getting worse”? Is it because the opposite of decline, “to increase” is usually associated with positive situations like growing or having more?
The main point I want to make is that we theoritcally could implement some crude form of emotional meaning by associating emotional concepts with physics based counterparts the same way we are doing it with all the other concepts.
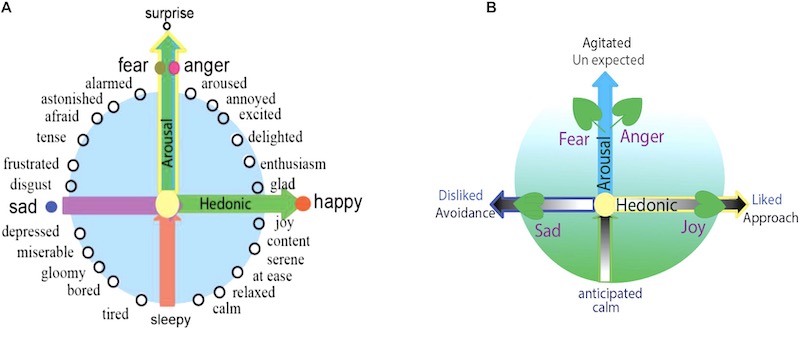
Check out this emotion model built from neuroscientists studying the common housefly.
Where to go from here?
So I built out a POC and learned a lot. I didn’t build the data structure and algorthm yet, but that is the main goal and so experimenting with that would be the next step. I want to continue writing more simulations and turn this into a living dictionary. Longer term I imagine this dataset could be used as a computer parseable wikipedia like Cyc. Or a standalone computer book to teach computers/humans like from the SciFi book The Diamond Age.
I purposely skipped doing any machine learning with this, but that would definitely be future direction to explore.
Check out all the work I did here and if any of this is interesting to you, please contact me.
