Deep Reinforcement Learning is a waste of time
Published Mon, Dec 30, 2019
Its the end of 2019 and I wanted to see how AI progress has been doing. Deep Reinforcement Learning (Deep RL) in particular has been hyped as the next evolutionary step towards Artificial General Intelligence (AGI), computer algorithms that can learn to do anything like humans in a general way.
Researchers have been working on Deep Reinforcement Learning (Deep RL) for a few years now with incremental progress. The idea and hope around Deep RL is that you could easily train an agent to do theoretically anything like drive a car, fold laundry, play video games, clean a house, solve a rubix cube, etc all without hand holding the learning process. Some of these experiments have resulted in some success, you can teach a Deep RL agent to play some video games and board games, but transferring anything to the real world, into production systems, has mostly been a failure. As of now, the end of 2019, I still do not know of any success stories for production system that use Deep RL.
Deep RL systems have multiple problems, I am not going to go into the details of them, there are a bunch of blog posts that already talk about these problems
I wouldn’t be surprised if at least some of those problems improve or get resolved, like finding more abstract ways to represent information inside of neural networks, but it doesn’t matter if you can’t solve what I consider the core issue: manual reward engineering. In Deep RL, I would say most of time is spent on engineering your reward function to get your agent to do what you want. The reward function is the objective function in more traditional machine learning terms, the algorithm uses this to know if it is heading in the right direction, the more reward it gets, the “better” the model does.
For example teaching a robotic arm to fold laundry, lets say you have a pile of pants, how do you write a reward function to fold them properly. It sounds easy when explaining this to another human, its just “fold the paints into neat piles” but a computer has no idea what any of these rules mean. For each experiment, you have to program your reward in a way that the computer can measure progress on its own, all without having any understanding of what its actually doing. So you might start off giving rewards for touching the pants, then more points for grasping the pants, or maybe points for moving the pants. How do you reward for the actual folding part? Does it get points for having 3 folds? How about points for no wrinkles? You end up spending so much time trying to guide the agent to follow the right path that its basically turned into a fully supervised problem. You theoretically could have a human watching the training process and then the human could assign scores for each action the system takes, but this does not scale. These Deep RL systems need to run anywhere from ten’s of thousands to millions of iterations trying out every variation of actions to figure out which are the right sequences to achieve their goal, a human could not possibly monitor all the steps the computer has taken. There is active research into trying to make this scale with Imitation Learning, but to me it’s just trying to improve something that is fundamentally broken.
During your journey of trying to train your laundry folding robot, you may need to constantly adjust the reward function as it accidentally rips the pants, drops the parts, folds them while being inside out, or folds them in weird ways that don’t seem to make any sense. Reward engineering turns into an experimental process of trial and error to find what works. There are countless documented reports of Deep RL models doing all kind of unexpected movements.
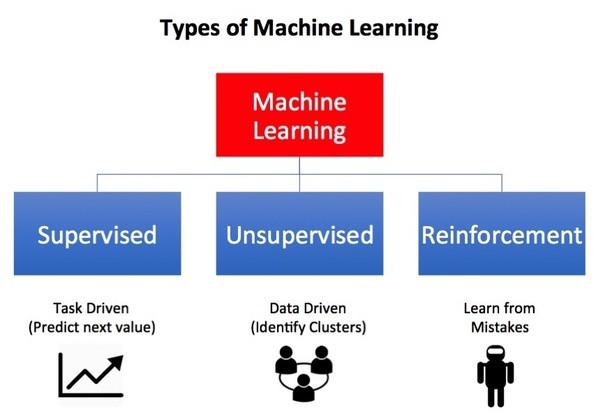 Reinforcement learning is typically classified as a separate 3rd class from supervised and unsupervised machine learning, but in my mind its currently really supervised learning. The current process is: you start training the model, then you watch it fall over and die, then you keep tweaking the reward function over and over for a very long time until maybe, just maybe you get a desired output. What part of that is not giving it training data? You’ve just convoluted the whole process and made everything more difficult by having to feed the answer in a non direct way to the agent. If computers are going to learn from their environment, it must happen in a 100% unsupervised manor.
Reinforcement learning is typically classified as a separate 3rd class from supervised and unsupervised machine learning, but in my mind its currently really supervised learning. The current process is: you start training the model, then you watch it fall over and die, then you keep tweaking the reward function over and over for a very long time until maybe, just maybe you get a desired output. What part of that is not giving it training data? You’ve just convoluted the whole process and made everything more difficult by having to feed the answer in a non direct way to the agent. If computers are going to learn from their environment, it must happen in a 100% unsupervised manor.
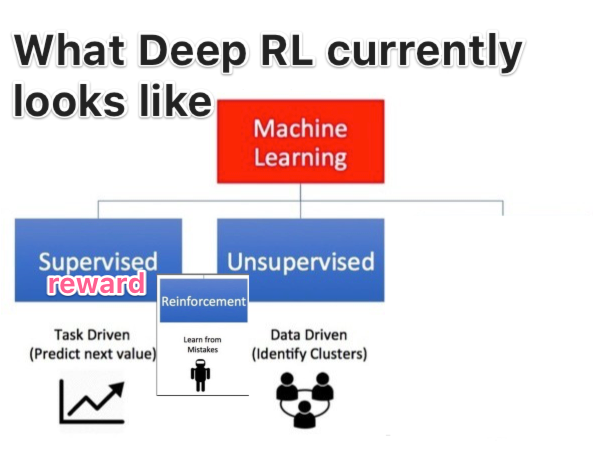
So why has there been so much hype around Deep Reinforcement Learning?
If you look at Deep RL from an abstract level, it is depicted as an agent that over time, learns from its environment. That seems absolutely correct and does mimic reality, all living organisms starting from birth learn how to live and navigate from and in their environment. We know this because we have done many experiments that empirically show us that if we change and constrain the environments for newborn organisms, they learn different things and behave differently. Deep RL is very different from traditional machine learning methods like supervised classification where a program gets fed raw data, answers, and builds a static model to be used in production.
The part that is wrong in the traditional Deep RL framework is the source of the signal. These artificial agents must learn directly from themselves and their environments, not some artificial reward function that we feed to them. When DeepMind came out with a single Deep RL agent that learned how to play Atari video games with almost no intervention, it was thought that this could scale up to all kinds of problems in other domains and potentially even AGI. What we’ve learned is that most things organisms and humans do, CANNOT be modeled as video games with agents optimizing for gaining as much reward as possible. And don’t be fooled by Deep RL winning games with no manual work, the reward engineering still happened, it just happened 40 years ago when the video games makers hired whole teams of people to make these games. Lots of people made this mistake thinking Deep RL was the next step in AGI, even Google was overzealous and spent $500+ million to buy DeepMind in the hopes of taking AI to the next level. It seems like the community latched on to the idea of Deep RL being the holy grail because it is the closest form of machine learning to sort of mimic our own reality, even though in reality its not even close.
What we’ve ended up with is lots of parlor tricks where little AI toys can play all kinds of video games, board games, and not much else.
The main benefit of going from more traditional machine learning methods to Deep Learning was that manual laborious engineering has been removed. You can theoretically give the model a bunch of data, run your optimization algorithm, and it would learn without you manually writing feature extraction code. So Deep Learning has been applied to part of reinforcement learning, mostly on the agent side taking in perception data in the form of pixels, but if you are still spending most of your time hand engineering the system, then in my mind its still doesn’t work.
I didn’t even go into detail of the other Deep RL problems like if you need to slight modify the objective, then get ready to retrain your whole system or that slight variations in the environment usually ends up in complete failure… AGI is on the way…….
So now we have the top machine learning research institutes, DeepMind and OpenAI, still spending the majority of their time and resources on Deep RL. They are constantly bombarding the internet with PR pieces showing the great progress they are making: Deep RL can play Go, StarCraft, Dota 2, solve a rubix cube, etc.
I am confused as to why they continue to spend so much time on building Deep RL systems that beat games with clearly defined rules and point systems. I think everyone gets it now, with enough time, money, and computers almost brute forcing every single possible action, Deep RL can beat almost any game. I believe a large portion of their strategy is to just pump out PR pieces with smoke and mirrors showing how the latest Deep RL system can beat the next best game so that they can continue to receive investments from people who don’t know better, just look at the recent $1 billion Microsoft gave OpenAI or the continued access to the Google piggybank for DeepMind. One of DeepMind’s recent successes (~5 years after the Google acquisition) is that they trained a single Deep RL agent to play Go, Chess, Shogi and Atari games. Yay, more video games!!!!!!
I’m not trying to beat up on them, I’m really happy they are around and actually making an effort to solve AGI. The problem is that they are creating LOTS of false perceptions which ends up wasting a lot of human brain power on dead ends and leads the general public to think we are lot closer to AGI when everyone in the industry knows its nowhere near. Secondly and more importantly, they are sending the wrong signal to the AI research population to spend more time on Deep RL. Many researchers and hackers look up to these companies and see these PR floods coming out of from them and spend countless hours hacking away at those same problems when they could be focusing their energy on bigger and more fundamental problems. If AI and AGI are going to move forward, I think its time to stop playing video games and focusing on harder problems.
Fortunately the DeepMind and OpenAI do spend time in other problem areas, but as I said, it seems like Deep RL is still their main focus.
Current Deep RL systems seem like they could be a good fit for systems that already have basic training. Think transfer learning where the agent already has a basic understanding of its environment and of itself. Watch a human child from birth, at first its starting to learn to see shapes and colors, move its fingers, touch objects, control its body, differentiate sounds, learn about gravity, physics, falling, squishiness, bounciness, learn object permeance, etc. All of that is happening to various degrees in every single living human and organism. Usually after a human baby has acquired a very large repertoire of knowledge: it can walk, grasp objects, use the bathroom, do basic talking, etc. Then more formal training happens like sending a child to school where it then goes through a more structured process of learning: homework, grading, and quizzing to train the child to learn from the curriculum. Current Deep RL systems seems like it could work really well for this kind of formalized training where the desired goal can be clearly and mostly automatically graded AND after the agent already has a basic grasp of its environment. If the child can’t recite ABC, fail, if they can recite the whole alphabet, pass. Currently Deep RL is putting the cart before the horse though, we are trying to train computers from scratch to do complicated tasks that may sometimes work, but because these models are trained for specific tasks versus generalization, they have no generalized understanding of their environment and end up with systems that are too brittle and don’t work very well. No amount of newer learning algorithms like back propagation, DQN, PPO, DDPG,TRPO are going to fix Deep RL as long as the source of the reward function is not fixed. I’m sure we will make incremental improvements and maybe get a few more points out of Starcraft, but its not going to make big efforts towards the holy grail of generalized artificial intelligence without a fundamental shift in architecture that allows the agent to learn in a fully unsupervised manner from its environment.
My own hypothesis is that the reward function for learning organisms is really driven from maintaining homeostasis and minimizing surprise. Homeostasis is the process that living things do to maintain stable conditions needed for survival. Every living organism must survive and maintain its body separate from the external environment. When its hungry, it feeds, when tired it sleeps, when thirsty it drinks, when hurt, it rests, when hunted, it evades, when too hot, it tries to cool down, etc. These innate and primordial signals tell the organism what to do and what to focus on as it navigates the environment. Failing to do these things results in failing to maintain homeostasis and ultimately an early death. As the organism is navigating around, it builds a model of its own sensorimotor interactions together with the environment as it interacts with its world. Its model starts to put things together: when dark, it should be cold, when I burp, I should hear a sound, when I move left, I expect to see vision to shift by X, as an animal walks in front of me, I expect it to continue moving forward, as I brush my finger on a cup, I expect to feel a smooth surface, when I make sounds through my vocal chords, I expect to hear a corresponding sound in my ears, etc. If anything unexpected happens, something that deviates from its model, then the model readjusts its predictions until it gets what it expects, which may result in more moving. If that fails, then genuine surprise occurs and those neurons are marked for “requiring model updates”, in which relearning and re-optimization may happen either in real time or while the organism is sleeping. Optimization occurs between the agent’s internal model of the environment and the actual environment and runs continuously to minimize surprise. These ideas have been discussed in neuroscience and philosophy for a long time by people like Andy Clark with his ideas on predictive processing and Karl Friston and his free energy principle. To my knowledge, I have not seen these ideas successfully deployed in machine learning environments yet. I believe there are many technical issues: how to mimic homeostasis in a computer, how the internal representation of the model should be stored, the low resolution between agents’ sensory apparatus and the environment, and low fidelity environments, among other issues.
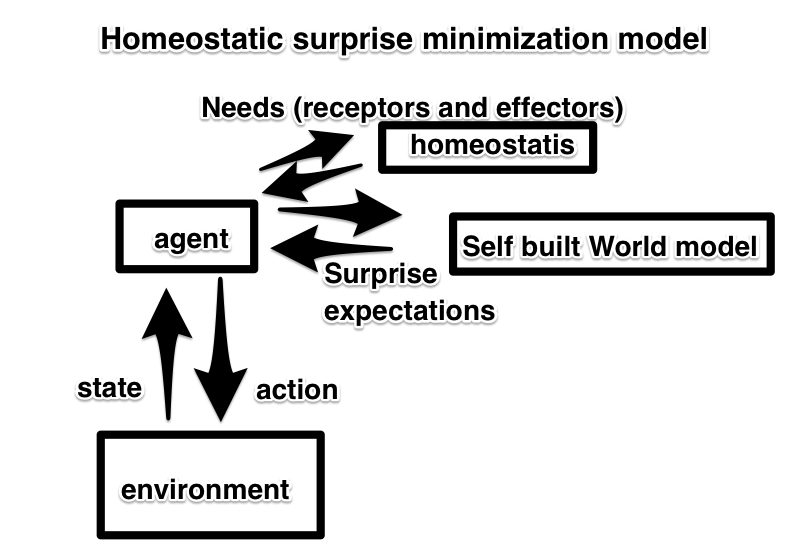
I did not mean to write this article with a flamebait title, but I couldn’t figure out a way to explain to people that the current Deep RL architecture is fundamentally flawed. We don’t need more models that can play more video games, we need to implement models that can learn generalized representations between the agent and their environment that can be learned in a fully unsupervised manor. This new architecture may be called Deep RL 3.0, active inference, predictive processing, or something totally different, but please stop wasting time on this dead end. Deep RL research has come up with some cool and interesting work, but its time to move on. Whoever can figure out a way to build the next general of AIs that can learn from their environment in an unsupervised way is going to make a HUGE difference and move the field forward.
